一、前言
最近需要处理一批数据,因为数据集比较大,处理一遍数据需要9.2秒,实在太慢了。
于是使用了一些简单的并行化方案,仅仅需要一两行代码,就能使处理速度提升到1.4秒,时间节省了差不多 85%!如果要处理的数据更大,则节省的时间更可观。
代码和实验如下。
二、实验条件
1. 数据
- culane 数据集,共 88880 个标注文本
- img_list文件,存放每个标注文件的位置
2. 基础代码
-
读取 img_list 文件到内存,获取 88880 个标注文本的路径
1 2 3
img_list = '/home/tianws/CULane/list/train.txt' with open(img_list, 'r') as f: lines = f.readlines()
-
对每个标注文本的路径进行处理,返回需要的 info
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
def load_culane_ann(img_path): """Load annotation from CULane style annotation file. Args: img_path (str): Path of annotation file. Returns: dict: Annotation info from culane ann. """ info = {} img_path = img_path.strip() # your process code here info['ann'] = ann return info
以上处理代码和本文无关,做了简化处理,可以替换成任何需要并行处理的代码。
三、方案
1. baseline: for loop
最传统的方法即为使用 for 循环,进行串行处理:
1
2
3
4
5
6
with Timer(print_tmpl='for loop takes {:.1f} seconds'):
data_infos = []
for line in lines:
info = load_culane_ann(line)
data_infos.append(info)
del data_infos
得到的输出为:
1
for loop tqdm takes 9.4 seconds
2. map
python 的 map 方法可以很简单地替换掉 for 循环,但本质也是串行处理:
1
2
3
4
with Timer(print_tmpl='map takes {:.1f} seconds'):
data_infos = map(load_culane_ann, lines)
data_infos = list(data_infos)
del data_infos
得到的输出为:
1
map takes 9.2 seconds
3. multiprocessing
multiprocessing 是 python 里的多进程包,通过它,我们可以在 python 程序里建立多进程来执行任务,从而进行并行计算。
multiprocessing 有很多复杂的用法,本文着眼于最简单方便的改造并行化,所以只使介绍最简单的方法。
(1) multiprocessing.Pool
作用于进程,可以指定进程数,默认cpu数量
1
2
3
4
5
6
from multiprocessing import Pool
with Timer(print_tmpl='Pool() takes {:.1f} seconds'):
with Pool() as p:
# with Pool(4) as p: # 指定4个进程
data_infos = p.map(load_culane_ann, lines)
del data_infos
得到的输出为:
1
2
3
4
5
Pool() takes 2.5 seconds
Pool(4) takes 2.9 seconds
Pool(8) takes 1.8 seconds
Pool(16) takes 1.4 seconds
Pool(32) takes 1.6 seconds
(2) multiprocessing.dummy.Pool
作用于线程,用法和上面一样,但是在我的任务中会更慢:
1
2
3
4
5
6
from multiprocessing.dummy import Pool as ThreadPool
with Timer(print_tmpl='ThreadPool() takes {:.1f} seconds'):
with ThreadPool() as p:
# with TreadPool(4) as p: # 指定4个线程
data_infos = p.map(load_culane_ann, lines)
del data_infos
得到的输出为:
1
2
3
4
ThreadPool() takes 37.4 seconds
ThreadPool(4) takes 29.4 seconds
ThreadPool(8) takes 33.3 seconds
ThreadPool(16) takes 34.4 seconds
4. p_tqdm
p_tqdm 是对 pathos.multiprocessing and tqdm 的包装库,可以对方便地对并行处理显示进度条,方法主要有如下几种:
- 并行 map:
- p_map - 并行有序 map
- p_umap - 并行无序 map
- 串行 map:
- t_map - 串行有序 map
使用方法和 map 一样,这里就列举一种:
1
2
3
with Timer(print_tmpl='p_map takes {:.1f} seconds'):
data_infos = p_map(load_culane_ann, lines)
del data_infos
得到的输出为:
1
2
3
4
5
6
100%|██████████████████████████████████████| 88880/88880 [05:28<00:00, 270.19it/s]
p_map takes 329.7 seconds
100%|██████████████████████████████████████| 88880/88880 [05:33<00:00, 266.75it/s]
p_umap takes 334.4 seconds
100%|█████████████████████████████████████| 88880/88880 [00:09<00:00, 9530.67it/s]
t_map takes 9.3 seconds
四、结论
由以上实验,可以统计各方案耗时如下: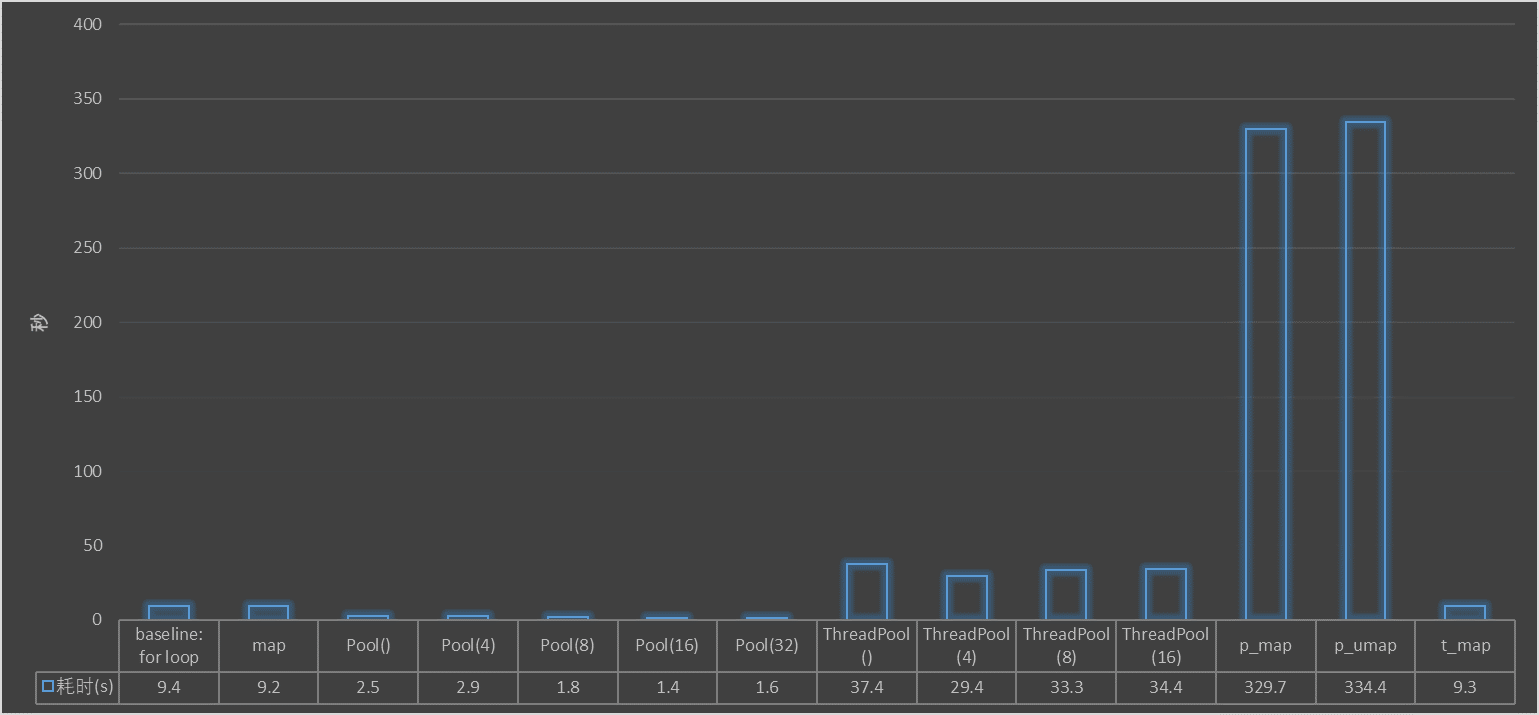
可以总结出一下结论:
- 几种顺序执行方案,时间差不多:baseline for loop、map、t_map;
- 基于进程的并行化 Pool,和基于线程的并行化 ThreadPool,具体哪个更快要根据具体情况实验分析,在本文中,因为数据放在ssd上,数据读取不是瓶颈,主要耗时在cpu处理上,所以基于进程的速度更快,基于线程的相反非常慢;相反如果是io密集型任务,数据读取是瓶颈,那么可能基于线程的 ThreadPool会更快;
- 进程数或者线程数设置得太大,或者太小,都会导致运行时间变长,可以根据自己的任务以及机器情况,试验设置合适的进程数;
- p_tqdm 库中的 p_map、p_umap 可以给并行处理显示进度条,但是运行时间变得太长了,不建议使用,如果想显示进度条,可以用 t_map 顺序处理,会更快,或者直接使用 tqdm 库;
本文介绍了几种方案,通过增加几行代码,就能使得 python 程序并行处理,使处理时间缩短约 85%,并实验量化分析了各方案的优缺点,附上了代码,读者可以根据自身任务尝试使用。
参考
- [python]map方法与并行执行
- Python Map 并行
- p_tqdm的p_map运行过慢
- 用 Python 实现并行计算
- Python多进程pool.map展示进度条方法
- 快速掌握用python写并行程序,干货满满
- 一行代码实现Python并行处理
知乎镜像地址:几种简单 python 并行化方法比较